
我有一个电子书阅读器,它是基于javafx的,支持一些常见的文件格式,最近我在翻阅电子书库的时候,发现一种很老的格式,它的后缀是umd,我找了一下,没有找到用于解析这玩意的类库,但是有很多文章说明其中的文件结构,因此我决定手动解析它。
UMD文件结构
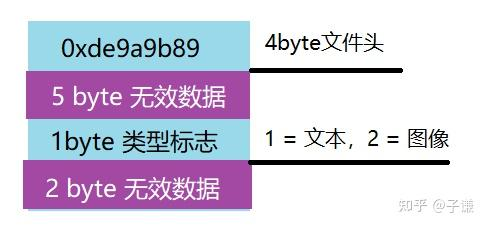
首先需要关注的是文件头的部分,UMD文件前四字节固定为0xde9a9b89,这表明它是一个UMD图书文件,接下来需要跳过5字节,然后是类型标志,本文只涉及此标志位1的文本类型,因为类型为2的我还没见过。
接下来跳过两个无效数据,就来到了第二部分——元数据。

元数据部分的结构如上图,首先会有一字节的分隔符,它是# 在UMD文件中,它用于区分各个部分,接下来一字节是metadata的类型,metadata一共有9个,分别是:
| 标志(无符号整数) | 类型 |
|---|---|
| 2 | 标题 |
| 3 | 作者 |
| 4 | 出版年 |
| 5 | 出版月 |
| 6 | 出版日 |
| 7 | 类型 |
| 8 | 出版社 |
| 9 | 经销商 |
| 11 | 未经压缩的内容总长度 |
元数据部分,每一个元数据之间都有#(1字节)分隔,后面2字节是上表左侧的数值,它们都为无符号整数,在使用Java解析的时候需要特别注意,它们应当是无符号的。
跳过一字节的无效数据后,接下来1字节是metadata的长度,通常国内的UMD制作时间比较早,它们通常会要求使用记事本的Unicode编码来保存文件,而这个Unicode并不是我们常说的UTF-8,而是UTF-16LE,因此应该使用UTF-16LE解析metadata以防止乱码,当然,win10以及更新的系统都会告诉你到底使用的是哪一种编码格式,在此之前,记事本的Unicode特指UTF-16LE。
这一字节的数值减去5,就是metadata的内容长度,读取此长度的数据并且转换为String后,继续读取下一字节,他应该是‘#’,也意味着那是下一个metadata的开始,到这里应该循环9次,依次读取这些metadata,它们的结构都是相同的。

在metadata部分后,出现的是章节偏移信息,第一个字节是#,表示是一个新的部分,接下来是固定的两字节,内容为0x0083,代表这里是章节的偏移信息,章节的偏移信息是指在正文内容解压后,这一章节开始与整个正文的第几字节。
跳过11字节的无效数据,接下来是4字节的无符号整数,将它减掉9并且除以4,得到章节数量,在这之后,就是章节偏移量的具体数值,有多少章节,就有多少章节偏移量的数值,它是一个4字节的无符号整数,数量与章节偏移量相同,使用循环来依次读取每一个偏移量即可。
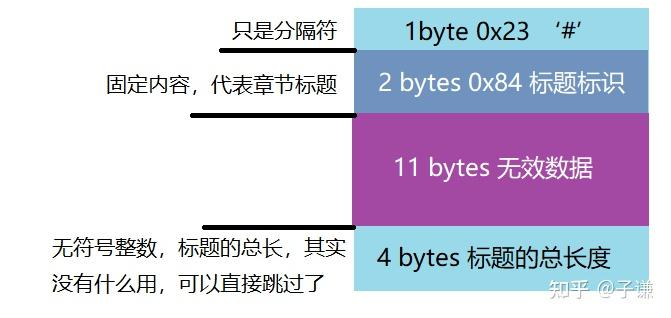
在偏移量读取完毕后,就能遇到下一个#分隔符了,同样它会占据一字节,接下来的是2字节的0x84,这代表接下来的数据是章节的标题,到了这里,可以之间跳过15字节,因为在之前以及读取到了章节数量,可以直接使用那个。
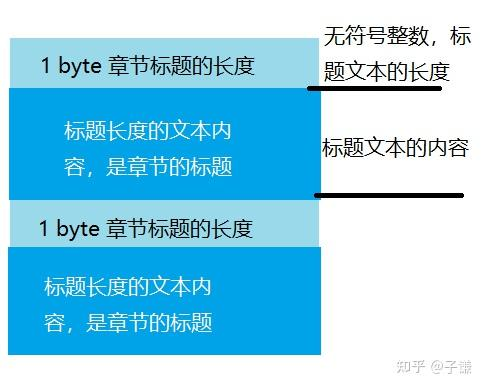
上图代表了一个章节标题的数据结构,首先读取1字节,这是标题文本的长度,它是一个无符号整数,接下来直接使用这个长度读取章节的标题,并且使用UTF-16LE编码为字符串——这就是章节的标题,我们之前得到了章节的数量,因此通过循环就能读取到每一个章节的标题。
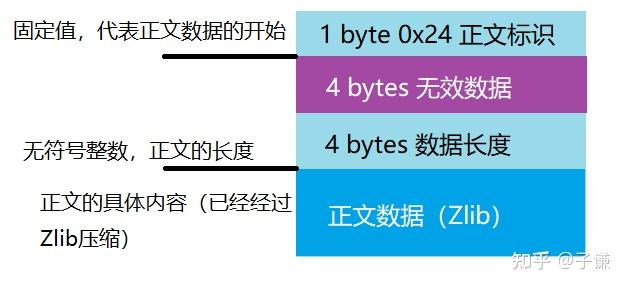
在标题得到正确的处理之后,接下来就是正文的内容了,正文由数据块组成,其中的内容经过了Zlib的压缩,因此需要按照数据块的结构进行读取,正文数据块开始的标志是0x24,在这之后,就是4字节的无效数据,直接跳过就好,紧接着就是4字节的无符号整数,此数值减去9就是被压缩的正文数据的长度。
读取压缩的数据后,如果下一字节是0x24,就按照上述的方法继续读取正文,但是如果不是,会有几种情况:
- 0x0A,遇到这个应该跳过6字节,读取下一字节如果是0x24,那么就应该从这里继续按照上述方法读取正文。
- 0xF1,遇到这个应该跳过18字节,读取下一字节如果是0x24,那么就应该从这里继续按照上述方法读取正文。
- 上述情况之外,通常代表正文已经结束,可以之间结束文件的读取,虽然接下来还有封面的图片,但是没有什么必要去读取它。
解析的具体实现方法
- 这种结构的文件非常适合使用RandomAccessFile进行读取,和IO流不同,这种类型可以随意读取文件的任意位置,通过其Seek方法能够很方便的移动读取的位置从而方便的实现随机读写。
- Java本身不支持无符号数值,但是这里常常会使用到,因此必须有方法让无符号数正确的读取为Java的普通int,对于byte,只需要和0xFF进行与运算即可,多个byte在与运算的基础上需要进行位移。
- Zlib的压缩算法其实就是Zip的Deflate,通过Java自带的Inflater就能做到解压。
- 按照文件的数据结构依次读取文件,就能够实现这种电子书的解析。
- 有一个很不好的地方,UMD存储的文本内容没有换行。
- 我实际上已经使用Java实现了此文件的解析功能.



发表回复